TL;DR
We propose PromptKD to distill student-friendly knowledge through prompt tuning and demonstrate for the first time that such knowledge is effective even in generative language models.

Figure. Comparison of instruction-following performance of KD methods using the GPT-2 model family. Owing to the student-friendly knowledge, our PromptKD outperforms others with only an additional 11K parameters. Dashed reference line represents the performance of the teacher model.
Abstract
Method Overview

Main Results
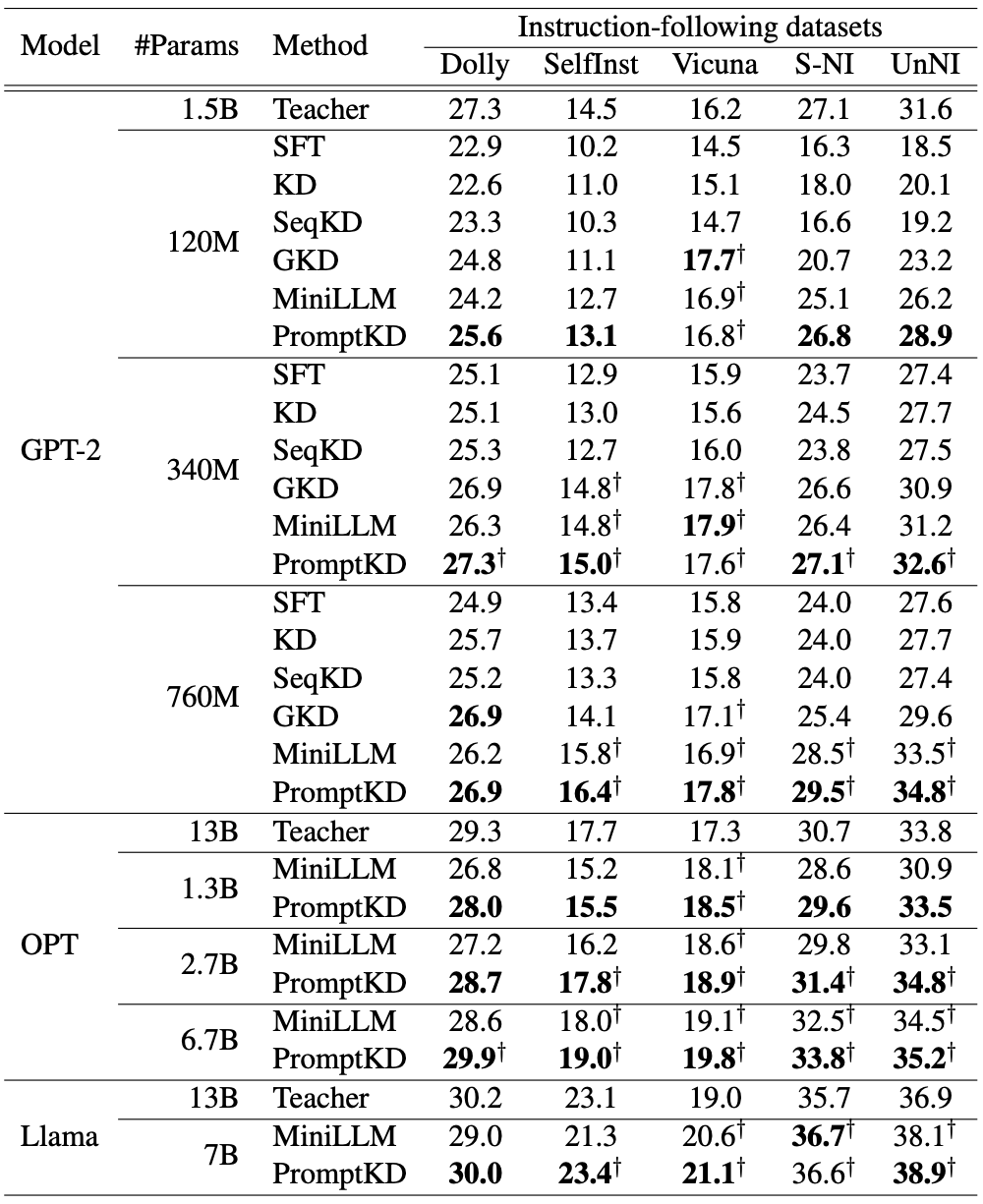
Table. Evaluation results on 5 instruction-following datasets. †Results surpass those of the teacher.
Analysis
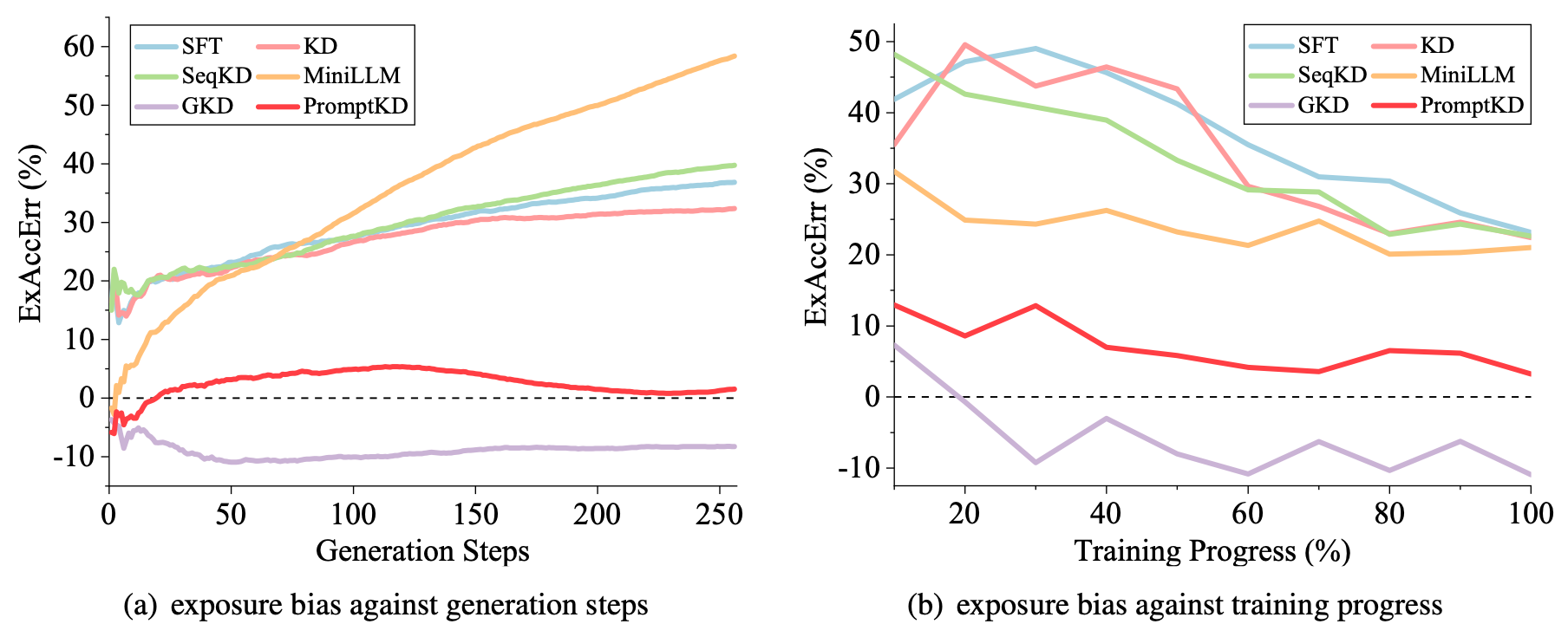
Figure. The measurement of exposure bias. Excess accumulated error (ExAccErr) is measured with respect to generation steps and training progress, where values closer to 0 indicate alleviation of exposure bias.

Table. Qualitative results of generated response from the Dolly validation set with and without using prompts for the Llama-13B teacher. A teacher with a prompt generates a response more similar to that of the student.
BibTeX
If you find our work useful, please cite our paper:
@inproceedings{kim-etal-2024-promptkd,
title = "PromptKD: Distilling Student-Friendly Knowledge for Generative Language Models via Prompt Tuning",
author = "Kim, Gyeongman and Jang, Doohyuk and Yang, Eunho",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2024",
year = "2024"
}